Understanding VGG16 Architecture: A Deep Learning Powerhouse

Introduction
VGG16 is a widely used deep convolutional neural network (CNN) architecture that has significantly contributed to computer vision tasks. Developed by the Visual Geometry Group (VGG) at Oxford, it gained popularity due to its simplicity and effectiveness in image classification tasks. This post will explore the architecture of VGG16, its key features, and how it performs image recognition.
What is VGG16?
VGG16 is a deep neural network consisting of 16 weight layers (convolutional and fully connected layers). It was introduced in the paper “Very Deep Convolutional Networks for Large-Scale Image Recognition” by Simonyan and Zisserman in 2014. The model achieved remarkable results in the ImageNet competition, making it one of the most influential deep learning architectures.
Architecture of VGG16
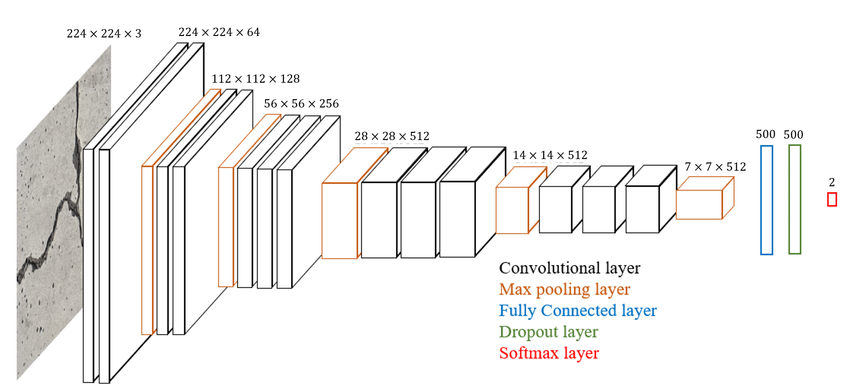
VGG16 follows a straightforward design pattern that consists of convolutional layers, max-pooling layers, and fully connected layers. The architecture can be broken down into five main blocks:
- Convolutional Layers: The network has 13 convolutional layers, each using a small 3×3 kernel with a stride of 1. These layers apply feature extraction operations to the input image.
- Max Pooling Layers: After every few convolutional layers, a 2×2 max pooling layer with a stride of 2 is applied to reduce spatial dimensions.
- Fully Connected Layers: The last part of the network consists of three fully connected layers, where the first two have 4,096 neurons, and the final one is the output layer.
- Activation Functions: All convolutional and fully connected layers use the ReLU activation function, except for the final layer, which uses softmax for classification.
- Output Layer: The final layer contains 1,000 nodes (for ImageNet classification), each representing a different class.
Key Features of VGG16
- Deep but Uniform Design: It uses multiple small filters (3×3) stacked together instead of large filters, improving feature learning.
- Large Number of Parameters: The network contains approximately 138 million parameters, making it computationally expensive but highly effective.
- Pretrained Weights Available: VGG16 can be used with pretrained weights on ImageNet, allowing transfer learning for various applications.
Applications of VGG16
VGG16 has been widely used in:
- Image Classification: Identifying objects in an image.
- Object Detection: Detecting multiple objects within an image.
- Feature Extraction: Extracting deep features for other machine learning models.
- Medical Image Analysis: Identifying patterns in medical imaging.
✅ Advantages:
- Simple and effective architecture.
- High accuracy on large-scale datasets.
- Useful as a feature extractor in transfer learning.
❌ Limitations:
- Large model size (requires significant memory and computation power).
- Slower training compared to newer architectures.
Conclusion
VGG16 remains a foundational deep learning model in computer vision. While newer architectures like ResNet and EfficientNet have improved upon its limitations, VGG16’s structured approach and pre-trained models make it a valuable tool for many applications.
Do you have experience using VGG16? Share your thoughts in the comments below!